 Here is a quick hack that I wrote. It's a Python library to search Google without using their API. It's quick and dirty, just the way I love it.
Here is a quick hack that I wrote. It's a Python library to search Google without using their API. It's quick and dirty, just the way I love it.
Why didn't I use Google's provided REST API? Because it says "you can only get up to 8 results in a single call and you can't go beyond the first 32 results". Seriously, what am I gonna do with just 32 results? I want to automate my Google hacks and I want millions of results. For example, I want to monitor popularity of keywords and websites, and to use it for various other reasons.
One of my next post is going to extend on this library and build a tool that checks your spelling and grammar. I have been using Google for a while now to check my spelling. For example, "across" vs. "accross". A common misspelling. The first one is correct and the second one is incorrect. Googling for these words reveal that the first has 323,136,000 results, but the second has 278,000 results, so I trust Google that the first spelling is more correct than the second one.
Subscribe to my posts via catonmat's rss, if you like this. I'll soon build this tool and you'll receive my posts automatically.
How to use the library?
First download the xgoogle library, and extract it somewhere.
- Download link: catonmat.net/ftp/xgoogle.zip
At the moment it contains just the code for Google search, but in the future I will add other searches (google sets, google suggest, etc).
To use the search, from "xgoogle.search" import "GoogleSearch" and, optionally, "SearchError".
GoogleSearch is the class you will use to do Google searches. SearchError is an exception class that GoogleSearch throws in case of various errors.
Pass the keyword you want to search as the first parameter to GoogleSearch's constructor. The constructed object has several public methods and properties:
- method get_results() - gets a page of results, returning a list of SearchResult objects. It returns an empty list if there are no more results.
- property num_results - returns number of search results found.
- property results_per_page - sets/gets the number of results to get per page. Possible values are 10, 25, 50, 100.
- property page - sets/gets the search page.
As I said, get_results() method returns a SearchResult object. It has three attributes -- "title", "desc", and "url". They are Unicode strings, so do a proper encoding before outputting them.
Here is a screenshot that illustrates the "title", "desc", and "url" attributes:
 Google search result for "catonmat".
Google search result for "catonmat".
Here is an example program of doing a Google search. It takes the first argument, does a search on it, and prints the results:
from xgoogle.search import GoogleSearch, SearchError
try:
gs = GoogleSearch("quick and dirty")
gs.results_per_page = 50
results = gs.get_results()
for res in results:
print res.title.encode("utf8")
print res.desc.encode("utf8")
print res.url.encode("utf8")
print
except SearchError, e:
print "Search failed: %s" % e
This code fragment sets up a search for "quick and dirty" and specifies that a result page should have 50 results. Then it calls get_results() to get a page of results. Finally it prints the title, description and url of each search result.
Here is the output from running this program:
Quick-and-dirty - Wikipedia, the free encyclopedia Quick-and-dirty is a term used in reference to anything that is an easy way to implement a kludge. Its usage is popular among programmers, ... http://en.wikipedia.org/wiki/Quick-and-dirty Grammar Girl's Quick and Dirty Tips for Better Writing - Wikipedia ... "Grammar Girl's Quick and Dirty Tips for Better Writing" is an educational podcast that was launched in July 2006 and the title of a print book that was ...Writing - 39k - http://en.wikipedia.org/wiki/Grammar_Girl%27s_Quick_and_Dirty_Tips_for_Better_Writing Quick & Dirty Tips :: Grammar Girl Quick & Dirty Tips(tm) and related trademarks appearing on this website are the property of Mignon Fogarty, Inc. and Holtzbrinck Publishers Holdings, LLC. ... http://grammar.quickanddirtytips.com/ [...]
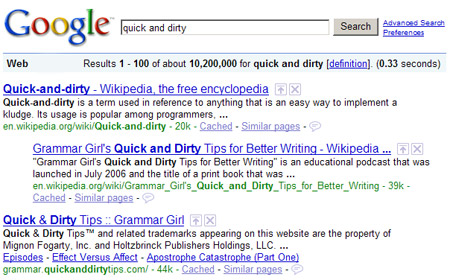 Compare these results to the output above.
Compare these results to the output above.
You could also have specified which search page to start the search from. For example, the following code will get 25 results per page and start the search at 2nd page.
gs = GoogleSearch("quick and dirty")
gs.results_per_page = 25
gs.page = 2
results = gs.get_results()
You can also quickly write a scraper to get all the results for a given search term:
from xgoogle.search import GoogleSearch, SearchError
try:
gs = GoogleSearch("quantum mechanics")
gs.results_per_page = 100
results = []
while True:
tmp = gs.get_results()
if not tmp: # no more results were found
break
results.extend(tmp)
# ... do something with all the results ...
except SearchError, e:
print "Search failed: %s" % e
You can use this library to constantly monitor how your website is ranking for a given search term. Suppose your website has a domain "catonmat.net" and the search term you want to find your position for is "python videos".
Here is a code that outputs your ranking: (it looks through first 100 results, if you need more, put a loop there)
import re
from urlparse import urlparse
from xgoogle.search import GoogleSearch, SearchError
target_domain = "catonmat.net"
target_keyword = "python videos"
def mk_nice_domain(domain):
"""
convert domain into a nicer one (eg. www3.google.com into google.com)
"""
domain = re.sub("^www(\d+)?\.", "", domain)
# add more here
return domain
gs = GoogleSearch(target_keyword)
gs.results_per_page = 100
results = gs.get_results()
for idx, res in enumerate(results):
parsed = urlparse(res.url)
domain = mk_nice_domain(parsed.netloc)
if domain == target_domain:
print "Ranking position %d for keyword '%s' on domain %s" % (idx+1, target_keyword, target_domain)
Output of this program:
Ranking position 6 for keyword python videos on domain catonmat.net Ranking position 7 for keyword python videos on domain catonmat.net
Here is a much wicked example. It uses the GeoIP Python module to find all 10 websites for keyword "wicked code" that are physically hosting in California or New York in USA. Make sure you download GeoCityLite database from "http://www.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz" and extract it to "/usr/local/geo_ip".
import GeoIP
from urlparse import urlparse
from xgoogle.search import GoogleSearch, SearchError
class Geo(object):
GEO_PATH = "/usr/local/geo_ip/GeoLiteCity.dat"
def __init__(self):
self.geo = GeoIP.open(Geo.GEO_PATH, GeoIP.GEOIP_STANDARD)
def detect_by_host(self, host):
try:
gir = self.geo.record_by_name(host)
return {'country': gir['country_code'].lower(),
'region': gir['region'].lower()}
except Exception, e:
return {'country': 'none', 'region': 'none'}
dst_country = 'us'
dst_states = ['ca', 'ny']
dst_keyword = "wicked code"
num_results = 10
final_results = []
geo = Geo()
gs = GoogleSearch(dst_keyword)
gs.results_per_page = 100
seen_websites = []
while len(final_results) < num_results:
results = gs.get_results()
domains = [urlparse(r.url).netloc for r in results]
for d in domains:
geo_loc = geo.detect_by_host(d)
if (geo_loc['country'] == dst_country and
geo_loc['region'] in dst_states and
d not in seen_websites):
final_results.append((d, geo_loc['region']))
seen_websites.append(d)
if len(final_results) == num_results:
break
print "Found %d websites:" % len(final_results)
for w in final_results:
print "%s (state: %s)" % w
Here is the output of running it:
Found 10 websites: www.wickedcode.com (state: ca) www.retailmenot.com (state: ca) www.simplyhired.com (state: ca) archdipesh.blogspot.com (state: ca) wagnerblog.com (state: ca) answers.yahoo.com (state: ca) devsnippets.com (state: ca) friendfeed.com (state: ca) www.thedacs.com (state: ny) www.tipsdotnet.com (state: ca)
You may modify these examples the way you want. I'd love to hear what you can come up with!
And just for fun, here are some other simple uses:
You can make your own Google Fight:
import sys
from xgoogle.search import GoogleSearch, SearchError
args = sys.argv[1:]
if len(args) < 2:
print 'Usage: google_fight.py "keyword 1" "keyword 2"'
sys.exit(1)
try:
n0 = GoogleSearch('"%s"' % args[0]).num_results
n1 = GoogleSearch('"%s"' % args[1]).num_results
except SearchError, e:
print "Google search failed: %s" % e
sys.exit(1)
if n0 > n1:
print "%s wins with %d results! (%s had %d)" % (args[0], n0, args[1], n1)
elif n1 > n0:
print "%s wins with %d results! (%s had %d)" % (args[1], n1, args[0], n0)
else:
print "It's a tie! Both keywords have %d results!" % n1
- Download google_fight: google_fight.py
- Download url:
https://catonmat.net/ftp/google_fight.py
Here is an example usage of google_fight.py:
$ ./google_fight.py google microsoft google wins with 2680000000 results! (microsoft had 664000000) $ ./google_fight.py "linux ubuntu" "linux gentoo" linux ubuntu wins with 4300000 results! (linux gentoo had 863000)
After I wrote this, I generalized this Google Fight to take N keywords, and made their passing to program easier by allowing them to be separated by a comma.
import sys
from operator import itemgetter
from xgoogle.search import GoogleSearch, SearchError
args = sys.argv[1:]
if not args:
print "Usage: google_fight.py keyword one, keyword two, ..."
sys.exit(1)
keywords = [k.strip() for k in ' '.join(args).split(',')]
try:
results = [(k, GoogleSearch('"%s"' % k).num_results) for k in keywords]
except SearchError, e:
print "Google search failed: %s" % e
sys.exit(1)
results.sort(key=itemgetter(1), reverse=True)
for res in results:
print "%s: %d" % res
Download google_fight2: google_fight2.py
Download url: https://catonmat.net/ftp/google_fight2.py
Here is an example usage of google_fight2.py:
$ ./google_fight2.py earth atmospehere, sun atmosphere, moon atmosphere, jupiter atmosphere earth atmospehere: 685000 jupiter atmosphere: 31400 sun atmosphere: 24900 moon atmosphere: 8130
Earth atmosphere wins!
Download xgoogle Library and Examples
Download xgoogle: xgoogle.zip
Download url: https://catonmat.net/ftp/xgoogle.zip
Download google fight: google_fight.py
Download url: https://catonmat.net/ftp/google_fight.py
Download google fight2: google_fight2.py
Download url: https://catonmat.net/ftp/google_fight2.py
Next, I am going to expand on this library and add search for Google Sets, Google Sponsored Links, Google Suggest, and some other Google searches. Then I'm going to build various tools, such as a sponsored links competitor finder and use Google Suggest together with Google Sets to genate more phrases. See you soon!