 Here is another quick hack that I wrote a while ago. It complements the xgoogle library that I published in my previous post with an API for Google Sponsored Links search.
Here is another quick hack that I wrote a while ago. It complements the xgoogle library that I published in my previous post with an API for Google Sponsored Links search.
Let me quickly explain why this library is useful, and what the Google Sponsored Links are.
For a typical search, Google shows regular web search results on the left side of the page, and "Sponsored Links" in a column on the right side. "Sponsored" means the results are pulled from Googe's advertising network (Adwords).
Here is a screenshot that illustrates the Sponsored Links:
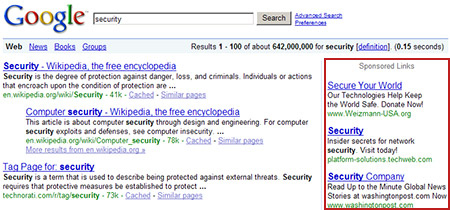 Google Sponsored Links results for search term "security" are in red.
Google Sponsored Links results for search term "security" are in red.
Okay, now why would I need a library to search the Sponsored results? Suppose that I am an advertiser on Adwords, and I buy some software related keywords like "video software". It is in my interests to know my competitors, their advertisement text, what are they up to, the new players in this niche, and their websites. Without my library it would be practically impossible to keep track of all the competitors. There can literally be hundreds of changes per day. However, with my library it's now piece of cake to keep track of all the dynamics.
How does the library work?
The sponsored links library pulls the results from this URL: http://www.google.com/sponsoredlinks. Here is an example of all the sponsored results for a query "security":
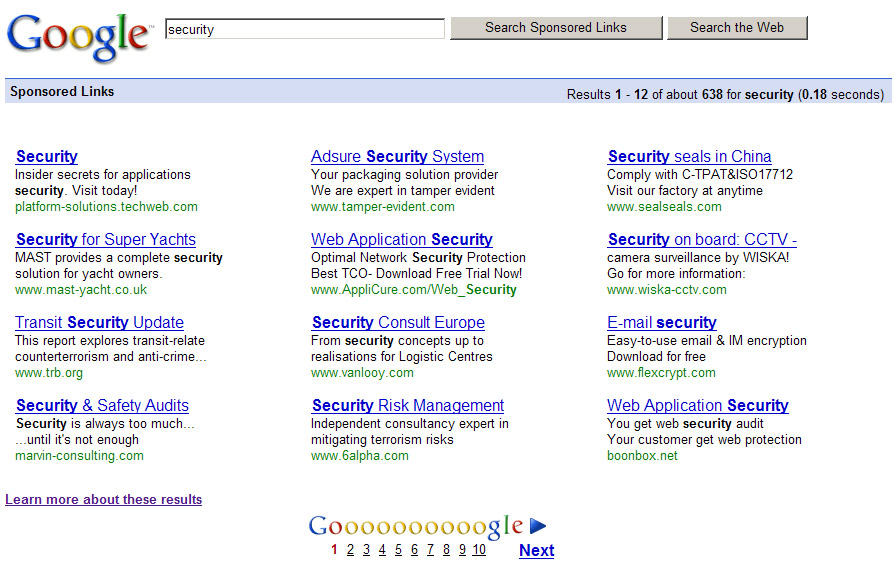 Sponsored links results for "security".
Sponsored links results for "security".
The library just grabs page after page, calls BeautifulSoup, and extracts the search result elements. Elementary.
How to use the library?
As I mentioned, this library is part of my xgoogle library. Download and extract it first:
- Download link: catonmat.net/ftp/xgoogle.zip
Now, the source file that contains the implementation of this library is "xgoogle/sponsoredlinks.py". To use it, do the usual import "from xgoogle.sponsoredlinks import SponsoredLinks, SLError".
SponsoredLinks is the class that provides the API and SLError is exception class that gets thrown in case of errors, so it's a good idea to import both.
The SponsoredLinks has a similar interface as the xgoogle.search (the plain google search module). The constructor of SponsoredLinks takes the keyword you want to search for, and the constructed object has several public methods and properties:
- method get_results() - gets a page of results, returning a list of SponsoredLink objects. It returns an empty list if there are no more results.
- property num_results - returns number of search results found.
- property results_per_page - sets/gets the number of results to get per page (max 100).
The returned SponsoredLink objects have four attributes -- "title", "desc", "url", and "display_url". Here is a picture that illustrates what each attribute stands for:
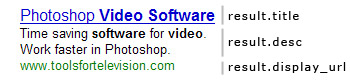
The picture does not show the "display_url" attribute as it's the actual link the result links to (href of blue link in the pic).
Here is an example usage of this library. It retrieves first 100 Sponsored Links results for keyword "video software":
from xgoogle.sponsoredlinks import SponsoredLinks, SLError
try:
sl = SponsoredLinks("video software")
sl.results_per_page = 100
results = sl.get_results()
except SLError, e:
print "Search failed: %s" % e
for result in results:
print result.title.encode('utf8')
print result.desc.encode('utf8')
print result.display_url.encode('utf8')
print result.url.encode('utf8')
print
Output:
Photoshop Video Software Time saving software for video. Work faster in Photoshop. www.toolsfortelevision.com http://www.toolsfortelevision.com ...
That's about it for this time. Use it to find your competitors and outsmart them!
Download xgoogle Library
For your convenience, here's xgoogle download link one more time:
Next time I am going to expand the library for Google Sets search. See you then!