We all know the regular expression character classes, right? There are 12 standard classes:
[:alnum:] [:digit:] [:punct:] [:alpha:] [:graph:] [:space:] [:blank:] [:lower:] [:upper:] [:cntrl:] [:print:] [:xdigit:]
But have you seen a visual representation of what these classes match? Probably not. Therefore I created a visualization that illustrates which part of the ASCII set each character class matches. Call it a cheat sheet if you like:
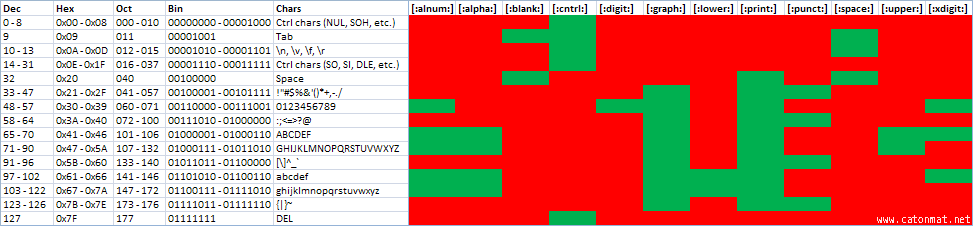 small version, large version
small version, large version
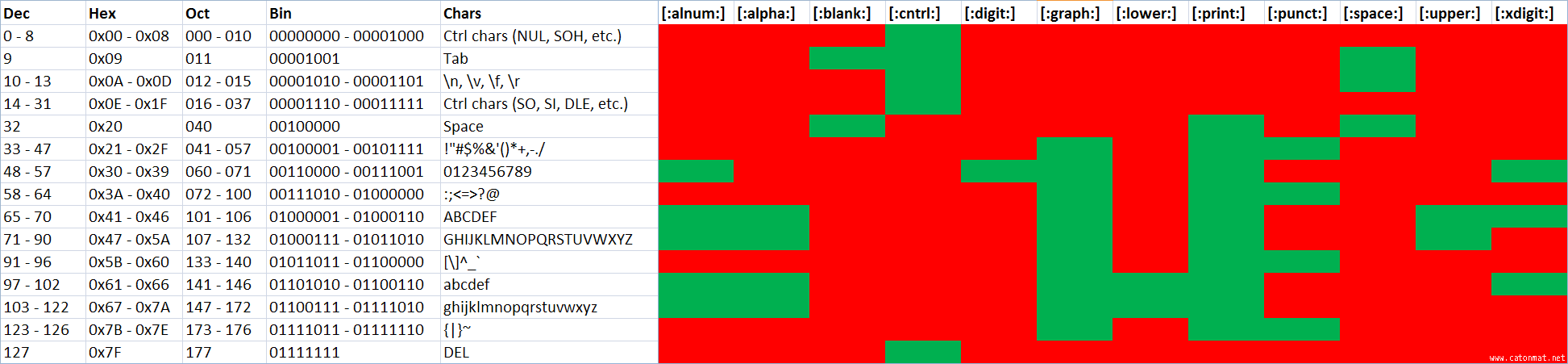{kind=link}
A bunch of programs that I used
Just for my own reference, in case I ever need them again, here are the one-liners I used to create this cheat sheet:
perl -nle 'printf "%08b - %08b\n", map { hex "0x".(split / /)[0], hex "0x".(split / /)[1] } $_ '
perl -nle 'printf "%03o - %03o\n", map { (split / /)[0], (split / /)[1] } $_'
And I used this perl program to generate and check the red/green matches:
use warnings;
use strict;
my $red = "\e[31m";
my $green = "\e[32m";
my $clear = "\e[0m";
my ($start, $end) = @ARGV;
die 'start or end not given' unless defined $start && defined $end;
my @classes = qw/alnum alpha blank cntrl digit graph lower print punct space upper xdigit/;
for (map { chr } $start..$end) {
for my $class (@classes) {
print "${green}1${clear}" if /[[:$class:]]/;
print "${red}0${clear}" unless /[[:$class:]]/;
}
print "\n"
}
Credits
I was inspired to create this visualization when I saw a similar table for C's ctype.h character classification functions.