 I have subscribed to quite a few programming blogs, one of them being Coding Horror.
I have subscribed to quite a few programming blogs, one of them being Coding Horror.
Coding Horror is written by Jeff Atwood and it's currently the top programming blog with 93 thousand feed subscribers.
Something that caught my attention on CodingHorror is that its traffic stats are publicly available.
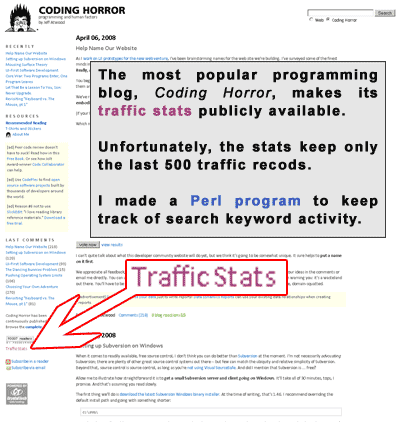
The statistics are hosted by StatCounter.com, which keeps only the last 500 entries of any traffic activity.
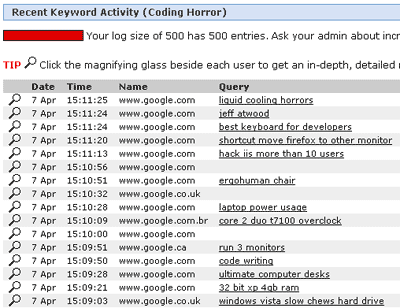
I wanted to see a clearer picture of the most popular keywords people searched for and ended up in Coding Horror blog.
Thirty minutes later I had written a Perl program, which accessed the statcounter.com statistics, parsed the "Recent Keyword Activity" page, extracted the keywords, and inserted them in an SQLite database.
I always love to describe how my programs work. I'll make it short this time, as we are concentrating on the statistics and not on programming.
The Perl Program
The Perl program uses (or reuses) a few CPAN modules:
- WWW::Mechanize to access the statcounter.com website,
- HTML::TreeBuilder to parse the keywords HTML page,
- Date::Parse to easily convert date and time string to a UNIX timestamp,
- and finally DBI and DBD::SQLite to access the SQLite database.
The program takes two optional arguments
- -nodb not to insert the keywords in database (just print them out)
- number - number of pages to extract keywords from
Here is the source code of the codinghorror_kwstats.pl program:
#!/usr/bin/perl
#
# Peteris Krumins (peter@catonmat.net), 2008
# https://catonmat.net -- good coders code, great reuse
#
# Access codinghorror.com traffic statistics and extract a few pages of latest search queries
# Released under GNU GPL
# 2008.04.08: Version 1.0
#
#
# run it as 'perl codinghorror_kwstats.pl [-nodb] [number of pages to extract]'
# -nodb specifies not to insert keywords in database, just print them to stdout
#
use strict;
use warnings;
use DBI;
use WWW::Mechanize;
use HTML::TreeBuilder;
use Date::Parse;
# URL to publicly available codinghorror's statcounter stats
my $login_url = 'http://my.statcounter.com/project/standard/stats.php?project_id=2600027&guest=1';
# Query used to INSERT a new keyword in the database
my $insert_query = 'INSERT OR IGNORE INTO queries (query, unix_date, human_date) VALUES (?, ?, ?)';
# Path to SQLite database
my $db_path = 'codinghorror.db';
# Insert queries in database or not? Default, yes.
my $do_db = 1;
# Number of pages of keywords to extract. Default 1.
my $pages = 1;
for (@ARGV) {
$pages = $_ if /^\d+$/;
$do_db = 0 if /-nodb/;
}
my $dbh;
$dbh = DBI->connect("dbi:SQLite:$db_path", '', '', { RaiseError => 1 }) if $do_db;
my $mech = WWW::Mechanize->new();
my $login_req = $mech->get($login_url);
unless ($mech->success) {
print STDERR "Failed getting $login_url:\n";
print $login_req->message, "\n";
exit 1;
}
unless ($mech->content =~ /Coding Horror/i) {
# Could not access Coding Horror's stats
print STDERR "Failed accessing Coding Horror stats\n";
exit 1;
}
my $kw_req = $mech->follow_link(text => 'Recent Keyword Activity');
unless ($mech->success) {
print STDERR "Couldn't find 'Recent Keyword Activity' link";
print $kw_req->message, "\n";
exit 1;
}
for my $page (1..$pages) {
my $tree = HTML::TreeBuilder->new_from_content($mech->content);
my $td_main_panel = $tree->look_down('_tag' => 'td', 'class' => 'mainPanel');
unless ($td_main_panel) {
print STDERR "Unable to find '<td class=mainPanel>'";
exit 1;
}
my $table = $td_main_panel->look_down('_tag' => 'table', 'class' => 'standard');
unless ($table) {
print STDERR "Unable to find 'table' tag";
exit 1;
}
my @trs = $table->look_down('_tag' => 'tr');
my $idx = 0;
for my $tr (@trs) {
next unless $idx++;
my @tds = $tr->look_down('_tag' => 'td');
unless (@tds == 6) {
print STDERR "<td> count was not 6!\n";
next;
}
my ($date, $time, $query) = map { $_->as_text } (@tds[1..2], $tds[4]);
next unless $query;
my $year = (localtime)[5] + 1900;
my $ydt = "$date $year $time";
my $unix_date = str2time($ydt);
print "$date $year $time: $query\n";
$dbh->do($insert_query, undef, $query, $unix_date, $ydt) if $do_db;
}
if ($page != $pages) {
my $page_req = $mech->follow_link(text => $page + 1);
unless ($page_req) {
print STDERR "Couldn't find page ", $page + 1, " of keywords", "\n";
exit 1;
}
}
}
Download: catonmat.net/ftp/codinghorror_kwstats.perl
Here is an example run of the program:
$ ./codinghorror_kwstats.pl -nodb 2 8 Apr 2008 03:50:54: media player 8 Apr 2008 03:50:53: physical working environment programmers 8 Apr 2008 03:50:26: nano itx case 8 Apr 2008 03:50:23: how to clean some internet spyware or adware infection 8 Apr 2008 03:50:23: mercurial install tutorial windows 8 Apr 2008 03:50:22: iis 5.1 multiple websites 8 Apr 2008 03:50:17: javascript integer manipulation comparision 8 Apr 2008 03:50:16: build machines pc 8 Apr 2008 03:50:14: manage remote desktop connections 8 Apr 2008 03:50:07: check that all variables are initialized 8 Apr 2008 03:50:00: powergrep older version 8 Apr 2008 03:49:43: software counterfeiting 8 Apr 2008 03:48:59: floppy emulator windows xp 8 Apr 2008 03:48:35: safari rendering cleartype 8 Apr 2008 03:48:18: captchas goole broken 8 Apr 2008 03:48:11: vs2005 ide color 8 Apr 2008 03:47:55: optimising dual core for cubase sx3 8 Apr 2008 03:47:44: micosoft project scheduling 8 Apr 2008 03:47:36: dont buy from craig at australian computer resellers 8 Apr 2008 03:47:32: large scale stored procedures 8 Apr 2008 03:47:31: free diff tool 8 Apr 2008 03:46:58: games that support 3 monitors 8 Apr 2008 03:46:56: firefox multiple times same stylesheet 8 Apr 2008 03:46:48: asp.net system.data.sqltypes.sqlnullvalueexception 8 Apr 2008 03:46:37: apple software serial code blocker 8 Apr 2008 03:46:31: beautiful code jon bentley 8 Apr 2008 03:46:28: system.web.httpparseexception 8 Apr 2008 03:46:23: round in c#.net 8 Apr 2008 03:46:15: project postmortem software 8 Apr 2008 03:45:43: programming fun 8 Apr 2008 03:45:33: sending messages over ip using command prompt 8 Apr 2008 03:45:26: where did horror develop?
The SQLite Database
The database has just one table called 'queries' which contains a 'query', 'unix_date' and 'human_date' columns. The 'unix_date' column is used for sorting the entries chronologically, and 'human_date' is there just so I could easily see the date.
Here is the schema of the database:
CREATE TABLE queries (id INTEGER PRIMARY KEY, query TEXT, unix_date INTEGER, human_date TEXT); CREATE UNIQUE INDEX unique_query_date ON queries (query, unix_date);
As the Perl program is run periodically, it might extract the same keywords several times. I created a UNIQUE index on 'query' and 'unix_date' fields, and left the job to drop the duplicate records to SQLite.
The Perl program uses the following SQL query to insert the data in database:
INSERT OR IGNORE INTO queries (query, unix_date, human_date) VALUES (?, ?, ?)
The 'OR IGNORE' makes sure the duplicate records get silently discarded.
Simple Statistics
I have been collecting keywords since March 31, and the database has now grown to a size of 73'336 records and 7MB (3MB compressed).
Download: catonmat.net/ftp/codinghorror-keyword-database.zip
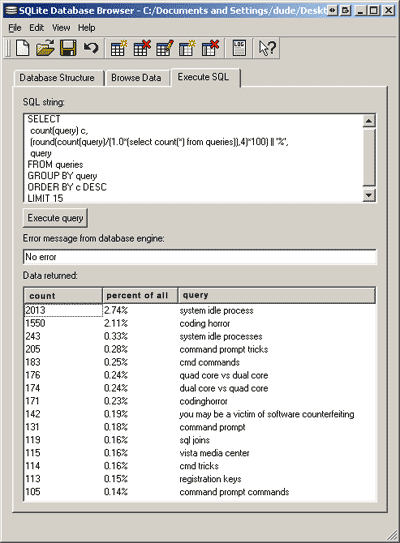
I ran a few simple SQL queries against the data using the GUI SQLite Database Browser to find the most popular keywords. I recommend downloading it, if you want to play around with the database.
The first query selected the 15 most popular keywords, along with their count, and percentage of all keywords.
The following SQL query did it:
SELECT count(query) c, (round(count(query)/(1.0*(select count(*) from queries)),3)*100) || '%', query FROM queries GROUP BY query ORDER BY c DESC LIMIT 15
I also made a bar chart using the public Google Charts API:
This chart would look much better if it had vertical bars. I couldn't figure out how to add keywords nicely below each bar, though.
Here is how the messy query to Google Charts API looks like:
http://chart.apis.google.com/chart?chtt=Coding%20Horror's%20Top%2015%20Keywords&cht=bhs&chd=t:100,77,12.07,10.18,9.09,8.74,8.64,8.49,7.05,6.51,5.91,5.71,5.66,5.61,5.22&chs=400x450&chxt=x,y&chxl=0:|0|2013|1:|command%20prompt%20commands|registration%20keys|cmd%20tricks|vista%20media%20center|sql%20joins|command%20prompt|you%20may%20be%20a%20victim...|codinghorror|dual%20core%20vs%20quad%20core|quad%20core%20vs%20dual%20core|cmd%20commands|command%20prompt%20tricks|system%20idle%20processes|coding%20horror|system%20idea%20process
Just to illustrate various ways to work with SQLite database, I did the same query from command line, and queried top 50 popular keywords, here they are:
$ sqlite3 ./codinghorror.db sqlite> .header ON sqlite> .explain ON sqlite> SELECT count(query) c, query FROM queries GROUP BY query ORDER BY c DESC LIMIT 50; c query ---- ------------- 2013 system idle process 1550 coding horror 243 system idle processes 205 command prompt tricks 183 cmd commands 176 quad core vs dual core 174 dual core vs quad core 171 codinghorror 142 you may be a victim of software counterfeiting 131 command prompt 119 sql joins 115 vista media center 114 cmd tricks 113 registration keys 105 command prompt commands 105 jeff atwood 99 quad core 96 dell xps m1330 review 89 rainbow tables 84 what is system idle process 82 software counterfeiting 80 fizzbuzz 78 laptop power consumption 77 quad core vs duo core 75 sql join 74 dell xps m1330 74 hard drive temperature 74 vista memory usage 73 source control 70 linked in 69 pontiac aztec 66 pontiac aztek 64 m1330 review 63 cracking 61 consolas 60 captcha 56 hyperterminal 56 ikea jerker 55 code horror 55 polling rate 55 source safe 54 coding horrors 54 dual core or quad core 54 programming quotes 54 visual source safe 53 logparser 51 sourcesafe 51 superfetch 51 three monitors 50 windows experience index
Knowing the most popular keywords can give you some hints what topics to write about on your blog. For example, an article named 'Windows Command Prompt Tricks' would start bringing good traffic from search engines instantly!
I did another bunch of queries to find the most popular programming languages on Coding Horror. I put the languages I could think of in langs.txt file, and ran the following Perl one-liner:
$ perl -MDBI -wlne 'BEGIN { $, = q/ /; $dbh = DBI->connect(q/dbi:SQLite:codinghorror.db/); } print +($dbh->selectrow_array(qq/SELECT count(query) FROM queries WHERE query LIKE "$_" OR query LIKE "$_ %" OR query LIKE "% $_" OR query LIKE "% $_ %"/))[0], $_' langs.txt | sort -n -r
It produced the following output:
1127 visual studio 1087 c# 407 c 287 javascript 239 java 139 asp 104 visual basic 59 php 44 ruby 42 python 26 perl 22 lisp 19 erlang 3 pascal 1 tcl 1 prolog 0 ml 0 haskell
I added 'visual studio' to the list of programming languages, as every beginner thinks it actually is a programming language. There were no keywords matching 'C++' because most search engines think of '+' as an operator rather than a valid search string.
I must say that Python is the answer to life, the universe and everything, as it was searched for 42 times!
Here is the same data put on a chart:
Here are some of the most popular search queries among programming languages:
- c# vs. vb.net
- javascript visualization
- c programmer blogs
- natural sort in java
- asp captcha
- php captcha breaker
If you're interested in this data, then use the download link below to download the database.
Downloads
Download Perl program: codinghorror_kwstats.perl
Download SQLite database(3 MB): codinghorror-keyword-database.zip
See you next time!